Global Health for Engineers
Mortenson Center in Global Engineering
University of Colorado Boulder
Course Structure
An introduction to the professional field of Global Health, particularly focused on the areas of global health that engineers often contribute to – i.e. community environmental health. In a short course, we won't have time to touch on things like health systems organization but there are many resources for additional learning.
We will be reading published peer reviewed studies of global health interventions – learning how to search for, read and analyze these kinds of studies is fundamental to being conversant in the field of global health. Many of these papers have engineers as co-authors.
This class is also an opportunity for group and 1:1 discussion. I am happy to meet with each of you individually to discuss career objectives and networking.
Class will be heavy on case studies, with student-led facilitation.
All readings posted in Canvas. Textbook is self-paced with online Canvas quizzes.
See Canvas Syllabus for link to class schedule.
Evan Thomas
Professor
- Environmental Engineering Program
- Civil, Environmental and Architectural Engineering Dept.
- Aerospace Engineering Sciences Department
Mortenson Endowed Chair in Global Engineering
Director, Mortenson Center in Global Engineering
University of Colorado Boulder
- PhD, Aerospace Engineering Sciences, 2009
- MS, Aerospace Engineering Sciences, 2006
- BS, Aerospace Engineering Sciences, 2005
- BS, Broadcast Journalism, 2005
Oregon Health and Science University
- MPH, Master in Public Health, 2014
Fletcher School at Tufts University
- Global MBA, 2022
NASA Johnson Space Center, Aerospace Engineer, 2004-2010
Portland State University, Assistant/Associate Professor, 2010-2018
Virridy Inc, Founder and CEO, 2012 – Present
Manna Energy Limited / DelAgua Health, Founder, COO, 2007-2016
~80 journal articles, 10 patents, professional work in 16 countries




The Global Health Architecture
Understanding the major organisations and funding mechanisms that shape global health policy, programs, and research.
Multilateral Organisations
- WHO — sets norms, coordinates response, technical guidance
- UNICEF — child health, nutrition, immunisation, WASH
- World Bank — health system financing and development loans
Public-Private Partnerships
- Gavi — vaccine access for 1B+ children since 2000
- Global Fund — AIDS, TB, and malaria ($60B+ disbursed)
- CEPI — epidemic preparedness and vaccine R&D
Bilateral Aid Agencies
- USAID (US) — largest bilateral health donor (~$10B/yr)
- FCDO (UK), GIZ (Germany), JICA (Japan)
- PEPFAR — US HIV/AIDS programme, 25M+ on treatment
Philanthropic & Research
- Gates Foundation — largest private funder (~$7B/yr)
- Wellcome Trust — biomedical research in LMICs
- MSF / Red Cross — frontline emergency response
The next section examines what happens when this architecture is disrupted.
The Current State of Global Health
2025–2026: A period of unprecedented disruption to global health infrastructure.
USAID Shutdown
Timeline
- Jan 20, 2025: Executive Order freezing all foreign assistance funds for 90 days, including PEPFAR
- March 2025: Termination of 83% of USAID's 6,300 global initiatives
- Staff cut from 10,000 to 15 personnel
- Feb 2026: Congress passed $50B foreign aid bill to begin reinvestment
Projected Impact
- 9.4 million additional deaths projected by 2030 (The Lancet)
- 500,000–1,000,000 lives lost in 2025 alone (Center for Global Development)
- 2.3 million people on antiretroviral treatment lost support
- 12.5–17.9 million additional malaria cases projected
- 2.4 million people in Yemen lost food assistance
US Withdrawal from the WHO
What Happened
- Jan 20, 2025: Executive order giving one-year notice of withdrawal
- Jan 22, 2026: US formally withdrew from the WHO
- US historically contributed ~15% of WHO's total budget (~$1.28 billion annually)
- WHO cutting ~2,371 staff (25% reduction) by mid-2026
Consequences for Global Health
- Global Influenza Surveillance and Response System (GISRS) disrupted — seasonal flu vaccine formulation at risk
- 50-country disease surveillance network dismantled
- Emergency outbreak response time reverted from <48 hours to >2 weeks
- Pandemic preparedness infrastructure weakened
EPA Rollbacks, CDC Cuts & Domestic Health
EPA Regulatory Rollbacks
- 31 climate, air, and water pollution regulations rolled back
- Emissions reporting requirements for CO2, methane, and other GHGs eliminated
- Coal-fired power plant emission restrictions dismantled
- Air pollution-related deaths projected to increase by tens of thousands per year
CDC Budget & Workforce Cuts
- Proposed 53% budget reduction for FY 2026
- ~25% of CDC workforce cut by end of 2025
- 42,000 jobs lost nationwide if proposed cuts adopted
- 60+ CDC programs eliminated, including global HIV/AIDS prevention and global immunization
- Morbidity and Mortality Weekly Report (MMWR) staff fired
Surveillance & Preparedness
- 12+ health tracking programs eliminated (deaths, disease trends)
- Disease detectives, outbreak forecasters, and data offices cut
- Public Health Emergency Preparedness funding cut 52%
- Weakened capacity for early detection, outbreak investigation, and pandemic preparedness
Implications for Global Health Engineers
Funding Landscape Shift
Traditional USAID-funded pathways for global engineering projects are disrupted. New funding models needed — carbon credits, private sector, multilateral alternatives.
Surveillance Gaps
Engineers working in water, sanitation, and environmental monitoring face a world with weaker disease surveillance and slower outbreak response.
Domestic & Global Nexus
EPA rollbacks demonstrate that environmental health is not just a developing-country issue. Air and water quality challenges affect communities everywhere.
Local Capacity Building
With reduced external support, building local technical and institutional capacity is more critical than ever for sustainable health outcomes.
Data & Evidence
Loss of federal data collection increases the importance of independent monitoring, sensor networks, and digital MRV systems.
Discussion
How should the global health engineering community respond to these changes? What role can universities and the private sector play?
Intro to Global Health
Part 1 - Overview
What is Global Health?
"An area for study, research, and practice that places a priority on improving health and achieving equity in health for all people worldwide. Global health emphasizes transnational health issues, determinants, and solutions; involves many disciplines within and beyond the health sciences and promotes interdisciplinary collaboration; and is a synthesis of population-based prevention with individual-level clinical care."
— Consortium of Universities for Global Health
Overview Objectives
Define the determinants, including social and economic, that impact health.
Highlight the differences in disease and life expectancy between high- and low-income countries.
Identify some of the dynamics in developing countries that impact health trends.
Key Concepts
The determinants of health
The measurement of health status
The importance of culture to health
The global burden of disease
Key risk factors for health problems
Organisation of health systems
Disciplines: Public Health · Public Policy · Medicine · Social Sciences · Behavioural Sciences · Law · Economics · History · Engineering · Biomedical Sciences · Environmental Sciences · Anthropology
Disease & Determinants of Health
Examples of disease that disproportionately impact developing countries
- Malaria
- Diarrhea
- Pneumonia
- HIV / Aids
99% of the children under the age of 5 who die every year lived in developing countries.
Determinants of Health
- Genetics
- Age
- Gender
- Lifestyle choices
- Community influences
- Income status
- Geographical location
- Urbanization
- Climate Change
- Governance
- Culture
- Environmental factors
- Work conditions
- Education
- Access to health services
Multi-sectoral Dimension of the Determinants of Health
Malnutrition
More susceptible to disease and less likely to recover
Cooking with wood and coal
Lung diseases
Poor sanitation
More intestinal infections
Poor life circumstances
Commercial sex work and STIs, HIV/AIDS
Advertising tobacco and alcohol
Addiction and related diseases
Rapid growth in vehicular traffic
Road traffic accidents
One Health — Zoonotic Disease at the Human-Animal-Environment Interface
Emerging Zoonoses
75% of emerging infectious diseases are zoonotic. COVID-19, mpox, Ebola, avian influenza, and MERS all crossed from animals to humans.
Environmental Drivers
Deforestation, urbanization, intensive agriculture, and climate change increase contact between wildlife, livestock, and humans — creating spillover opportunities.
Engineering Role
Water and sanitation engineers work at the human-environment boundary. Wastewater surveillance, safe animal husbandry infrastructure, and environmental monitoring are engineering contributions to One Health.
Governance & Armed Conflict
Governance
Governance has a direct impact on socioeconomic status, health inequalities, and development
- Allocation of Resources
- Control of policy
- Trade agreements
- Regional politics
- Abuse of power
- Education
Armed Conflict
The Results:
- Disparities over resources and power
- Broken relationship with neighboring countries
- Lack of development
- Inequality along race/gender lines
- Resources diverted from health care to support conflict
- Displacement
Health Implications:
- Malnutrition
- Diarrhea
- Respiratory infections
- AIDS
- Extreme poverty
- Negative long-term effects on health
Intro to Global Health
Part 2 – Global Burden of Disease
Explore the Data
Interactive tools for exploring the Global Burden of Disease: GBD Compare | SDG Visualizations | Our World in Data
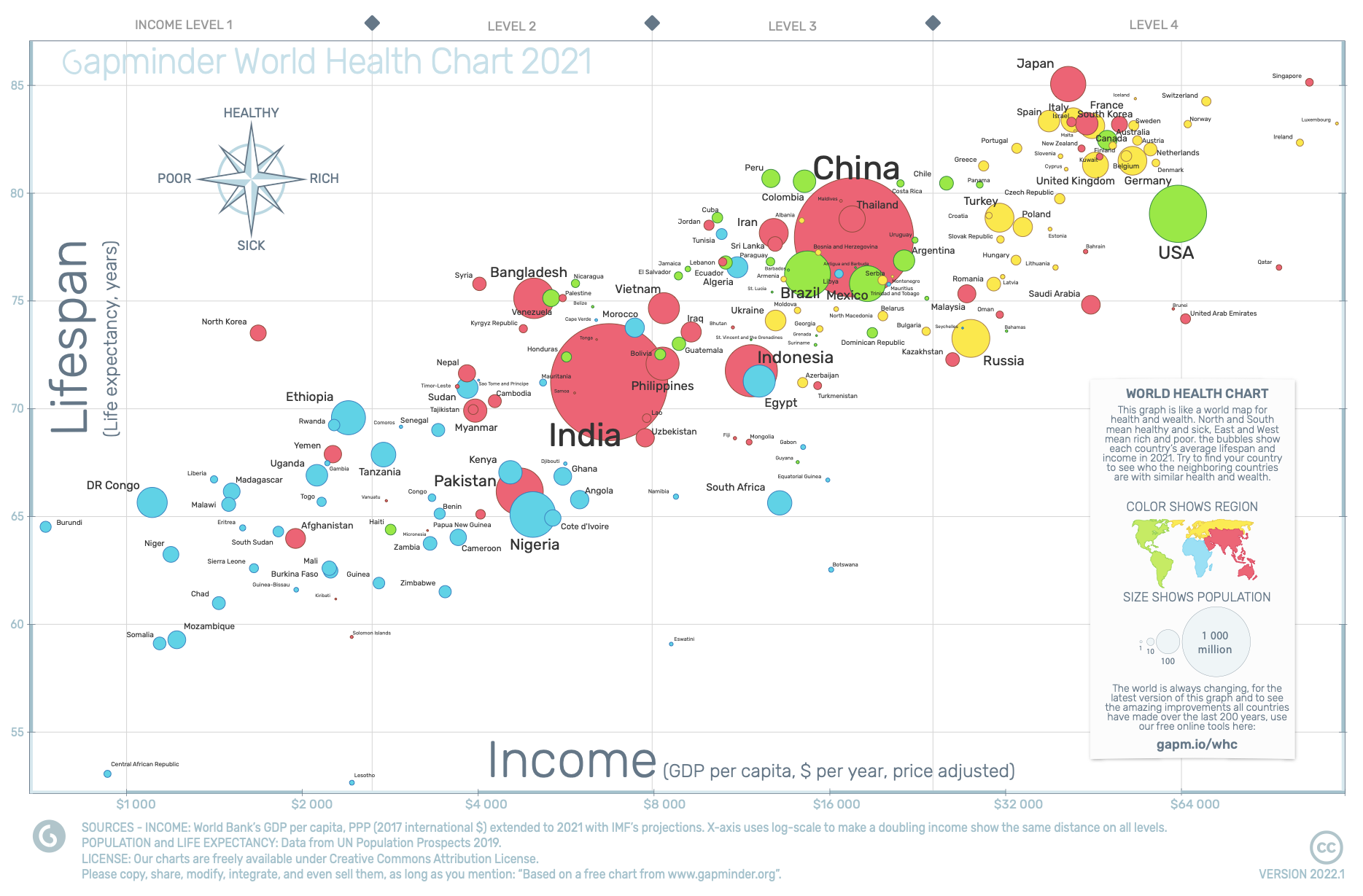
Health & Income of Nations
Life expectancy vs. GDP per capita. Bubble size = population, color = region. Source: World Bank / UN, 2023.
Global Mortality Among Children Under 5
Total deaths by cause, 1990–2021. Sources: IHME GBD 2021, UNICEF IGME 2024, WHO Global Health Estimates.
Child Mortality in Sub-Saharan Africa
Total under-5 deaths by cause, 1990–2021. Sources: IHME GBD 2021, WHO Africa Region, UNICEF IGME 2024.
Extreme Poverty by Region
People living below $2.15/day (2017 PPP). Sub-Saharan Africa is the only region where absolute numbers are rising. Source: World Bank, 2024. By 2030, 9 in 10 people in extreme poverty will live in Sub-Saharan Africa.
Per Capita CO2 Emissions
High-income countries have the highest per capita emissions, while low-income countries with the greatest disease burden contribute the least.
Global Burden of Disease
DALYs per 100,000 from all causes. Sub-Saharan Africa and South Asia bear the highest disease burden.
Undernourishment
Share of population with insufficient caloric intake. Malnutrition is a key determinant of susceptibility to disease.
Child Mortality — Causes of Death Under 5
4.9 million children under five died in 2024 — over 13,400 every day. Nearly 90% in LMICs.
The causes of death differ dramatically between high-income and low-income countries.
Low-Income Countries
High-Income Countries
Sources: IHME GBD 2021, UNICEF IGME 2024, WHO Global Health Estimates. Shares are % of total under-5 deaths.
Communicable & Non-Communicable Diseases
Communicable Diseases — Definition & Transmission
"Any condition transmitted directly or indirectly to a person from an infected person, animal, vector, or through the inanimate environment."
Direct transmission
- Blood-borne / sexual — HIV, Hepatitis B & C
- Inhalation — Tuberculosis, influenza, anthrax
- Food-borne — E. coli, Salmonella
- Contaminated water — Cholera, rotavirus, Hepatitis A
Indirect transmission
- Vector-borne — malaria, onchocerciasis, trypanosomiasis
- Fomites — contaminated objects and surfaces
- Zoonotic — animal-to-human (avian influenza, Ebola, MERS)
Key drivers of emergence (IOM)
- Globalisation — affordable international air travel, increased trade
- Microbial adaptation and drug resistance
- Breakdown of public health capacity
- Changing demographics, behaviour, land use, and urbanisation
Impact of Communicable Diseases
Disease Burden
- CDs account for ~30% of the global burden of disease and ~60% in Africa
- 40% of the disease burden in LMICs; disproportionately affects the poorest communities
- Most communicable diseases are preventable or treatable
Social Impact
- Disruption of family networks — child-headed households, social exclusion
- Stigma and discrimination — TB, HIV/AIDS, leprosy; affects employment, schools, migration
- Orphans and vulnerable children — loss of caregivers, exploitation and trafficking risks
- Quarantine measures may aggravate social disruption
Economic Impact
- Macro level: Tourism revenue drops 50–70% during outbreaks; malaria costs 1.3% of GDP annually in high-transmission countries
- Household level: Poorer households disproportionately affected; catastrophic treatment costs; lost productivity for both patient and caregiver
Malaria
In 2024, there were an estimated 282 million malaria cases in 80 countries worldwide
- An increase of 33 million cases since 2022
In 2024, malaria killed an estimated 610,000 people. Nearly every minute, a child under 5 dies from malaria.
Nearly half the world's population lives in areas at risk of malaria transmission.
The WHO African Region accounts for 94% of cases and 95% of deaths
- Children under 5 account for ~76% of all malaria deaths in the African Region
- Nigeria alone accounts for 31% of global malaria deaths
Source: WHO World Malaria Report 2025
Top 12 Highest-Burden Countries — Estimated Malaria Cases, 2024 (millions)
Source: WHO World Malaria Report 2025
Malaria Control
Malaria control
- Early diagnosis and prompt treatment to cure patients and reduce parasite reservoir
- Vector control:
- Indoor residual spraying
- Long lasting insecticide treated bed nets
- Intermittent preventive treatment of pregnant women
Challenges in malaria control
- Widespread resistance to conventional anti-malaria drugs
- Malaria and HIV
- Health Systems Constraints
- Access to services
- Coverage of prevention interventions
HIV/AIDS Infections Over Time
Global new HIV infections and AIDS-related deaths, 1990–2023 (millions)
Source: UNAIDS Global AIDS Update 2024; AIDSinfo
Global HIV Burden
39.9 million people living with HIV (2023)

HIV/AIDS
In 2023, 39.9 million people worldwide were living with HIV, of which 67% live in SSA
- 4.1 million people worldwide became newly infected
- 2.8 million people lost their lives to AIDS
New infections occur predominantly among the 15-24 age group.
First identified in the early 1980s. Has affected over 85 million people since the start of the epidemic.
Source: UNAIDS Global AIDS Update 2023
HIV Co-infections
Impact of TB on HIV
- TB considerably shortens the survival of people with HIV/AIDS.
- TB kills up to half of all AIDS patients worldwide.
- TB bacteria accelerate the progress of AIDS infection in the patient
HIV and Malaria
- Diseases of poverty
- HIV infected adults are at risk of developing severe malaria
- Acute malaria episodes temporarily increase HIV viral load
- Adults with low CD4 count more susceptible to treatment failure
Non-Communicable Diseases (NCDs)
NCDs — chronic diseases not transmitted person-to-person — kill 41 million people each year (74% of all global deaths). 77% of NCD deaths occur in low- and middle-income countries, where health systems are least equipped to manage them.
NCDs with highest impact in low-income countries
- Cardiovascular diseases — leading NCD killer globally (17.9M deaths/year); hypertension, rheumatic heart disease, and stroke are especially prevalent in SSA and South Asia
- Chronic respiratory diseases (4.1M deaths/year) — driven by household air pollution from cooking with solid fuels (wood, charcoal, dung); 2.3 billion people still rely on polluting fuels, causing 3.2M premature deaths/year
- Cancers (9.7M deaths/year) — cervical cancer (preventable via HPV vaccination) kills 350,000 women/year, 90% in LMICs; liver cancer linked to contaminated water and aflatoxin exposure
- Diabetes (2.0M deaths/year) — type 2 diabetes rising fastest in LICs due to nutrition transition; 1 in 2 adults with diabetes are undiagnosed
- Chronic kidney disease — strongly linked to contaminated drinking water (heavy metals, agrochemicals); CKD of unknown origin is epidemic in Central America, Sri Lanka, and parts of SSA
Environmental drivers in low-income settings
- Air pollution — ambient + household air pollution causes 6.7M deaths/year; 9 out of 10 people breathe polluted air; LICs bear the highest burden per capita
- Water quality — arsenic, fluoride, lead, and microbial contamination linked to cancers, kidney disease, skeletal fluorosis, and developmental harm in children; 2 billion people use contaminated water sources
- Sickle cell disease — 300,000+ births/year (75% in SSA); 50–80% of affected children in Africa die before age 5 without treatment
- Mental health — depression is the leading cause of disability in LMICs; treatment gap exceeds 90% in many low-income countries
Sources: WHO Global Status Report on NCDs 2024; WHO Household Air Pollution Fact Sheet 2024; Lancet Commission on Pollution and Health 2022
Air Quality and Public Health
Air pollution is the single largest environmental health risk — responsible for 6.7 million premature deaths annually worldwide.
Two major exposure types
- Ambient (outdoor) air pollution — 4.2M deaths/year; caused by vehicle emissions, industrial activity, power generation, and waste burning
- Household air pollution — 3.2M deaths/year; caused by burning solid fuels (wood, charcoal, coal, dung) for cooking and heating. Affects 2.3 billion people, predominantly in LMICs
Health effects
- Stroke and ischaemic heart disease (leading causes of air pollution deaths)
- COPD and chronic respiratory disease
- Lung cancer
- Acute lower respiratory infections in children
- Low birth weight, preterm birth, and impaired cognitive development
Key facts
- 9 out of 10 people breathe air exceeding WHO guideline limits
- LMICs bear the heaviest burden — 89% of air pollution deaths
- Children under 5 account for ~600,000 deaths from air pollution annually
- Household air pollution disproportionately affects women and girls, who spend the most time near cooking fires
Source: WHO Air Pollution Fact Sheets 2024; Lancet Commission on Pollution and Health 2022
Water and Public Health
“No other single intervention in the history of medicine has saved as many lives and reduced as much suffering as the provisioning of uncontaminated water,” - Paul Edward
One billion people in the world lack access to clean drinking water
- A leading cause of death worldwide
- An estimated 1.4 million people die each year from inadequate water, sanitation and hygiene
Source: WHO, 2023

Sanitation and Public Health
Minimum Standards
- Safe disposal excreta and sullage (greywater)
- Avoid disposal within 15 meters of any water source
- Provision of drainage
- Disposal of waste
- Control of insect and rodents


Epidemiology & Biostatistics
John Snow & the Birth of Epidemiology
In 1854, a devastating cholera outbreak struck London’s Soho district, killing over 600 people. The prevailing “miasma theory” blamed foul air, but physician John Snow suspected contaminated water. Through meticulous mapping of deaths and interviews with residents, Snow traced the outbreak to a single source: the Broad Street pump.

The Broad Street pump memorial, Broadwick Street, London
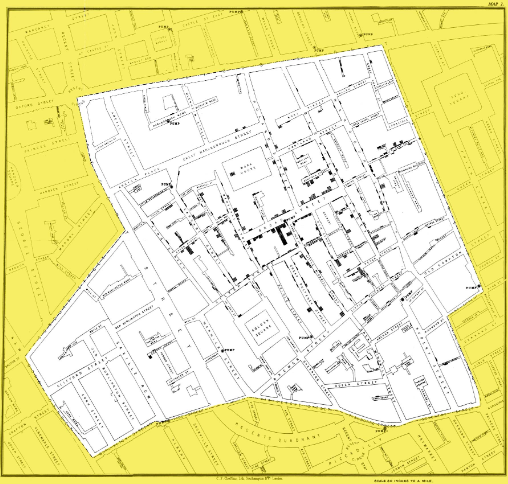
Snow’s dot map — each bar marks a cholera death, clustered around the Broad Street pump
Snow convinced local authorities to remove the pump handle, and the outbreak subsided. His work established the foundations of epidemiology: systematic data collection, spatial analysis, and evidence-based public health intervention — decades before germ theory was accepted.
Epidemiology — Defined
Adapted from: Last JM, ed. A dictionary of epidemiology. 2nd ed. Toronto, Canada: Oxford University Press; 1988.
Study of the distribution and determinants of health-related states among specified populations and the application of that study to the control of health problems
Purposes in Public Health Practice
- Discover the agent, host, and environmental factors that affect health
- Determine the relative importance of causes of illness, disability, and death
- Identify those segments of the population that have the greatest risk from specific causes of ill health
- Evaluate the effectiveness of health programs and services in improving population health
Epidemiology Key Terms
epidemic or outbreak: disease occurrence among a population that is in excess of what is expected in a given time and place.
cluster: group of cases in a specific time and place that might be more than expected.
endemic: disease or condition present among a population at all times.
pandemic: a disease or condition that spreads across regions.
rate: number of cases occurring during a specific period; always dependent on the size of the population during that period.
R0 (basic reproduction number):
The average number of people one infected person will transmit the disease to in a fully susceptible population. R0 > 1 means the epidemic grows; R0 < 1 means it dies out. COVID-19 original strain R0 ≈ 2.5; measles R0 ≈ 15.
Incidence vs. Prevalence
Incidence — the rate of new cases arising in a population over a defined time period.
- Incidence rate = new cases ÷ population at risk ÷ time
- Measures the risk of contracting a disease
Prevalence — the proportion of a population that has a condition at a specific point in time (or period).
- Point prevalence = existing cases ÷ total population
- Measures the burden of disease in a community
Example: Cholera in a Refugee Camp
- Camp population: 10,000
- 100 new cases per week → incidence = 10 per 1,000 per week
- Average illness lasts 5 days → ~71 active cases at any time → prevalence ≈ 0.7%
THE BATHTUB ANALOGY
🛁
Water flowing IN = new cases (incidence)
Drain = recovery or death
Water level = prevalence
High incidence + fast recovery = low prevalence
Low incidence + chronic disease = high prevalence
Measurement of Health Status
Life expectancy at birth — average years a newborn can expect to live given current mortality trends
Maternal mortality ratio — deaths from pregnancy-related complications per 100,000 live births
Infant mortality rate — deaths in infants under 1 year per 1,000 live births
Neonatal mortality rate — deaths under 28 days per 1,000 live births
Under-5 mortality rate — probability of dying before age 5, per 1,000 live births
GLOBAL COMPARISON
| Metric | Norway | Sierra Leone |
|---|---|---|
| Life expectancy | 83.3 yr | 55.3 yr |
| Maternal mortality | 2 | 443 |
| Infant mortality | 1.7 | 78.5 |
| Under-5 mortality | 2.4 | 105.6 |
Source: WHO Global Health Observatory, 2023
Understanding Dose-Response Curves
A dose-response curve describes the relationship between exposure to a substance (dose) and the resulting health effect (response).
Core Principles
- Threshold vs. non-threshold — some agents have a safe level; others (radiation, some carcinogens) do not
- Shape matters — linear, sigmoidal, supralinear, or U-shaped (hormesis)
- Key metrics — ED50 (effective dose for 50%), LD50 (lethal dose for 50%), NOAEL (no observed adverse effect level)
Example: Paracetamol (Acetaminophen)
- Therapeutic (500–1000 mg): pain relief
- Overdose (>4 g/day): liver toxicity
- Severe (>10 g): liver failure, death
The following slides apply dose-response thinking to water and air pollution.
SIGMOIDAL DOSE-RESPONSE CURVE
Paracetamol toxicity: sigmoidal curve from safe therapeutic range through liver damage threshold
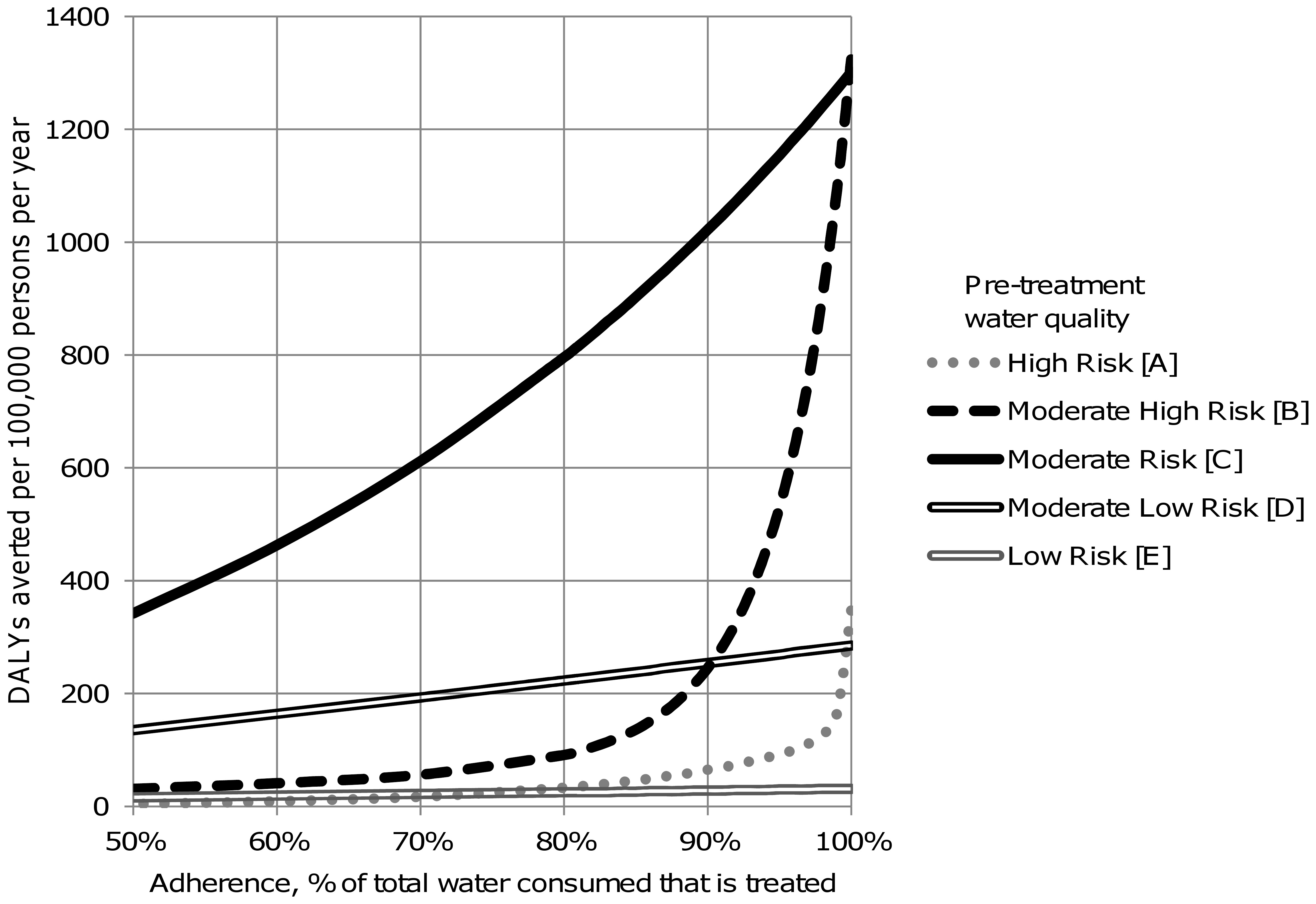
Dose-Response: Clean Drinking Water
The dose-response relationship for water quality interventions shows that health benefits increase with the level and consistency of adherence to clean water consumption.
Key observations
- Even partial adoption of improved water sources reduces diarrhoeal disease risk by 30–40%
- Consistent use of point-of-use treatment (filtration, chlorination) achieves the greatest reductions — up to 70–80% reduction in waterborne illness
- Intermittent use provides limited protection; compliance is critical to achieving the full dose-response benefit
- The curve is steepest at higher adherence levels — the last increment of compliance yields the largest marginal health gain
Source: Wolf et al., Cochrane Review on Water Quality Interventions, 2022
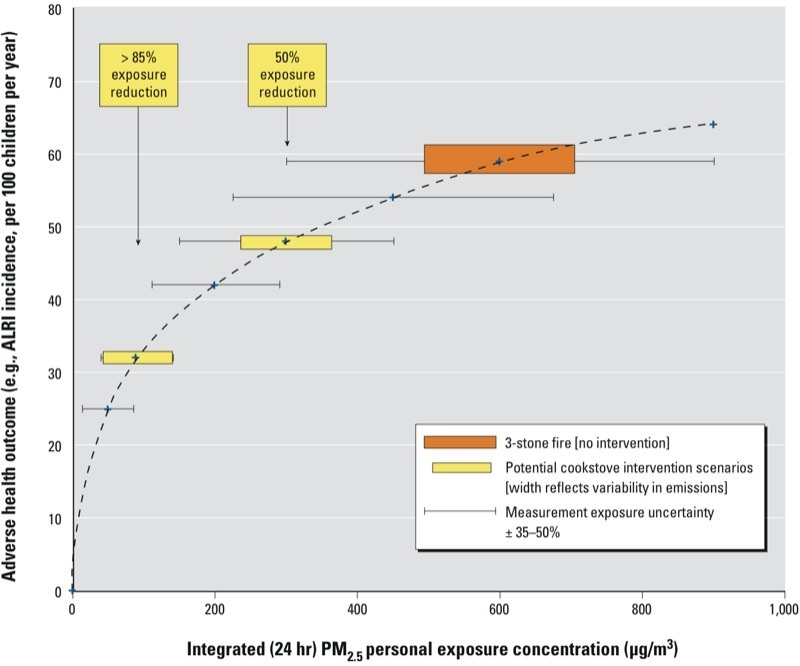
Dose-Response: Air Pollution Exposure
The dose-response curve for air pollution demonstrates a non-linear relationship between particulate matter (PM2.5) exposure and health outcomes, with the steepest risk at lower concentrations.
Key observations
- The curve is supralinear — health risk per unit of PM2.5 is greatest at lower exposure levels, meaning even small reductions in already-low pollution yield significant benefits
- At high exposure levels (common in LMICs), the curve flattens; large absolute reductions are needed to see proportional health improvement
- Household air pollution from solid fuel cooking (PM2.5 often exceeds 500 µg/m³) sits on the flat portion — switching to clean fuels produces a dramatic shift along the curve
- WHO guideline: annual mean PM2.5 < 5 µg/m³; 99% of the global population exceeds this threshold
Source: Global Burden of Disease Study 2021; Burnett et al., Integrated Exposure-Response Functions, 2014
Modern Scenario: COVID-19 Outbreak Investigation
Timeline
- Dec 2019: Cluster of pneumonia cases in Wuhan, China
- Jan 7, 2020: Novel coronavirus identified (SARS-CoV-2)
- Jan 20: Human-to-human transmission confirmed
- Jan 30: WHO declares Public Health Emergency
- Mar 11: WHO declares pandemic
- Dec 2020: First vaccines authorized
Epidemiological Lessons
- R0 drove policy: original ~2.5, Delta ~5, Omicron ~10+ — recall that R0 > 1 means exponential spread
- Wastewater surveillance emerged as a key engineering tool
- Genomic sequencing tracked variant evolution in real time
- Disparities: LMICs received vaccines months to years later
- 7+ million confirmed deaths globally by 2024 (true toll estimated 15–25M)
- mRNA vaccine platform: from sequence to authorized vaccine in 11 months
Apply your epi toolkit: This pandemic illustrates incidence (daily case curves), prevalence (active infections at peak), R0 (transmission potential), and confounding (did lockdowns reduce spread, or did behavior change independently?).
Epidemiology Study Types
EXPERIMENTAL
Researcher assigns the exposure
- Randomized Controlled Trial (RCT)
Gold standard — random assignment to treatment/control eliminates confounding. E.g., testing a new water filter vs. placebo. - Quasi-experimental
No random assignment. E.g., comparing villages that received a WASH program to those that did not.
OBSERVATIONAL
Researcher observes without intervening
Descriptive — who, where, when?
- Case report / series — detailed account of one or a few patients
- Cross-sectional survey — snapshot of a population at one point in time
Analytic — why? how?
- Cohort study — follows exposed vs. unexposed forward in time → yields Risk Ratio
- Case-control study — compares cases vs. controls backward → yields Odds Ratio
Confounding
A confounder is an extrinsic variable that is associated with both the exposure and the outcome, distorting the apparent relationship between them.
Solid = true effect; Dashed = confounding paths
WASH Example
Exposure: Boiling drinking water
Outcome: Less diarrhoea
Confounder: Household wealth
Wealthier households are more likely to boil water and have better nutrition, sanitation, and healthcare — inflating the apparent benefit of boiling alone.
Methods to Control
- Randomization (RCT)
- Stratification by confounder
- Matching cases & controls
- Multivariate regression
Measuring the Association between Exposure and Outcome
The appropriate measure of association to use depends on the nature of the data
When exposure and outcome variables are dichotomous (two-level nominal data)
- Odds ratio — use with case-control study (observational)
- Risk ratio — use with cohort study (controlled)
- Rate ratio — use with cohort study (controlled)
“Risk” refers to the probability of occurrence of an event or outcome.
“Odds” refers to the probability of occurrence of an event / probability of the event not occurring.
Epidemiological Formulas
Rate Formula
To calculate a rate, we first need to determine the frequency of disease, which includes:
the number of cases of the illness or condition
the size of the population at risk
the period during which we are calculating the rate
RATE FORMULA
Rate = Cases ÷ Population at risk × 100
2 × 2 TABLE
| Disease + | Disease − | |
|---|---|---|
| Exposed + | a | b |
| Exposed − | c | d |
OR = (a×d) / (b×c) RR = [a/(a+b)] / [c/(c+d)]
Worked Example: Odds Ratio
The odds ratio (OR) quantifies the association between an exposure and an outcome in a case-control study.
Interpreting the OR:
- OR = 1 — no association between exposure and outcome
- OR > 1 — exposure is associated with higher odds of disease
- OR < 1 — exposure is associated with lower odds (protective)
An OR of 2.97 means that smokers have approximately 3× the odds of developing lung cancer compared to non-smokers.
EXAMPLE: Smoking & Lung Cancer
| Cancer + | Cancer − | |
|---|---|---|
| Smokers | 688 | 650 |
| Non-smokers | 21 | 59 |
CALCULATION
OR = (688 × 59) / (650 × 21)
OR = 2.97
Smokers have ~3x the odds of lung cancer
Sensitivity & Specificity
Sensitivity — the ability of a test to correctly identify those with the disease (true positive rate).
Sensitivity = a / (a + c) — “Of all sick people, how many test positive?”
Specificity — the ability of a test to correctly identify those without the disease (true negative rate).
Specificity = d / (b + d) — “Of all healthy people, how many test negative?”
Predictive Values
- PPV = a / (a + b) — probability that a positive test is a true positive
- NPV = d / (c + d) — probability that a negative test is a true negative
- PPV depends heavily on prevalence: even a 99% specific test produces many false positives in low-prevalence settings
DIAGNOSTIC 2 × 2 TABLE
| Disease + | Disease − | |
|---|---|---|
| Test + | a (TP) | b (FP) |
| Test − | c (FN) | d (TN) |
TP = true positive, FP = false positive, FN = false negative, TN = true negative
Confidence Intervals, p-values & NNT
95% Confidence Interval
A range of values within which we are 95% confident the true population parameter lies.
- For an OR or RR: if the 95% CI includes 1.0, the result is not statistically significant
- Example: OR = 2.97 (95% CI: 1.83–4.82) — significant, because CI does not cross 1.0
- Wider CI = less precision (smaller sample size); Narrower CI = more precision
p-value
The probability of observing a result this extreme (or more) if the null hypothesis were true.
- Convention: p < 0.05 is considered “statistically significant”
- A small p-value does not prove causation or clinical importance
Number Needed to Treat (NNT)
The number of patients who need to receive a treatment for one additional patient to benefit.
NNT = 1 / ARR
ARR = Absolute Risk Reduction = riskcontrol − risktreatment
WASH Example:
- Diarrhoea risk without filter: 25%
- Diarrhoea risk with filter: 10%
- ARR = 0.25 − 0.10 = 0.15
- NNT = 1 / 0.15 ≈ 7
- For every 7 households given a filter, 1 case of diarrhoea is prevented
NNT is especially useful for comparing the cost-effectiveness of global health interventions.
Public Health Interventions
Digital Epidemiology — Engineering Tools for Disease Surveillance
Wastewater Surveillance
Monitoring SARS-CoV-2, influenza, RSV, and poliovirus in sewage provides population-level disease tracking without individual testing. Over 70 countries now have wastewater surveillance programs.
Mobile & Satellite Data
Mobile phone mobility data tracked COVID-19 spread in real time. Satellite imagery monitors environmental risk factors: flooding, deforestation, urban heat islands, and vector breeding habitats.
Sensor Networks & IoT
Continuous water quality sensors (like the Lume TLF sensor), air quality monitors, and connected diagnostic devices enable real-time environmental health surveillance at scale.
Surveillance & Public Health Approach
Goal of Intervention
Develop strategies for particular groups to engage in change toward health
Provide a support system to initiate change and sustain positive behaviors
A Public Health Approach
Surveillance → Risk Factor Identification → Intervention → Implementation → Evaluation
Surveillance
What is the problem?
Risk Factor ID
What is the cause?
Intervention
What works?
Implementation
How do you do it?
Evaluation
Did it work?
Approaches to Interventions
Personal responsibility and action
Utilitarian Approaches – "Greatest good for the greatest number"
- Including non Health Systems Interventions.
Regulations and Laws
Partnerships and Collaboration
Enlightened Self Interest
Education
Develop favorable attitudes towards the behavior
Training (i.e. Community health workers)
Participatory engagement
Provide sustainable access
Utilizing underlying skills of the local people
Supportive Environment
- Utilizing families, local organizations, community leaders, policy makers
Behavior Change
Why Do People NOT Change Behavior?
Do they understand the message?
Do they see themselves as vulnerable?
Do they trust the ones who present the message?
Do they think the benefits of change are worth the long-term benefits?
Is it too costly?
Does change contradict with their religious beliefs?
Health Belief Model
Perceived susceptibility – risk of acquiring the disease
Perceived severity – perception on the risk of acquiring the disease
Perceived benefits – is it worth the change?
Perceived barriers – obstacles to achieving health change
Cue to action – what will trigger this change?
Self-efficacy – how confident is the person to successfully perform a behavioral change?
Randomized Controlled Trial (RCT)
Efficacy vs. Effectiveness
Efficacy — Does the intervention work under ideal, controlled conditions? Participants are closely monitored, protocols are strictly followed, and non-compliant subjects may be excluded. Answers: "Can it work?"
Effectiveness — Does the intervention work under real-world conditions? Studies include typical populations, variable adherence, and routine delivery systems. Answers: "Does it work in practice?"
An intervention can show high efficacy but low effectiveness if uptake, adherence, or delivery is poor at scale — a common gap in global health programs.
Study Population
Treatment Group
Receives intervention
Control Group
No intervention / placebo
Compare Outcomes
Compare Outcomes
Cost-Effectiveness Analysis
With limited resources, decision-makers must prioritise interventions that produce the greatest health gain per dollar spent.
Key Concepts
- DALY (Disability-Adjusted Life Year) = YLL + YLD — one DALY = one lost year of healthy life
- ICER = ΔCost / ΔDALYs averted — the incremental cost per unit of health gained
- Willingness-to-pay threshold — WHO suggests 1–3× GDP per capita per DALY averted
Decision Rules
- ICER < GDP/capita → highly cost-effective
- ICER 1–3× GDP/capita → cost-effective
- ICER > 3× GDP/capita → not cost-effective
WASH Intervention Comparison
| Intervention | $/DALY averted |
|---|---|
| Oral rehydration salts | $50–100 |
| Point-of-use chlorination | $100–300 |
| Household water filters | $300–800 |
| Piped water to premises | $1,000–5,000 |
Estimates vary by context. Source: DCP3, WHO-CHOICE
Implementation Science
The study of methods to promote the adoption, fidelity, and sustainability of evidence-based interventions in real-world settings.
Adoption
Will the target population take up the intervention?
- Cultural acceptability
- Perceived benefit vs. cost
- Community champions & peer effects
Fidelity
Is it used correctly and consistently?
- Training quality & supervision
- Self-report vs. sensor gap (67% vs. 37%)
- Stove stacking — partial adoption
Sustainability
Will effects persist after external support ends?
- Funding model (carbon credits vs. aid)
- Local capacity & supply chains
- Government ownership
The gap between efficacy and effectiveness is almost always an implementation problem. The Rwanda case study illustrates all three challenges.
Health System Strengthening
Effective interventions require functioning health systems. The WHO framework identifies six building blocks essential to health system performance.
Service Delivery
Accessible, safe, quality health services that meet population needs
Health Workforce
Sufficient, skilled, motivated workers — Rwanda: 45,000 CHWs are the backbone
Health Information
Surveillance, vital registration, HMIS — data for decision-making
Medical Products
Medicines, vaccines, diagnostics — equitable access & supply chain
Financing
Adequate funding, risk pooling, universal health coverage goals
Leadership & Governance
Strategic policy, regulation, accountability, anti-corruption
Engineering contribution: Engineers build the infrastructure, information systems, supply chains, and monitoring tools that make health systems function. WASH infrastructure is a core building block.
Rwanda Tubeho Neza
Water Filter & Cookstove Programme
Rwanda — Country Context
Key Indicators
- Population: 14 million (2024)
- GDP per capita: ~$800
- Under-5 mortality: 38 per 1,000 live births
- Over 80% rely on firewood as primary fuel
- Most rural households drink untreated water
Study Location
Western Province, Rwanda — 96 sectors cluster-randomized, reaching 101,000 households with water filters and improved cookstoves.


Programme Implementation

LifeStraw Family 2.0 water filter in household

EcoZoom Dura improved cookstove in use

Electronic sensor monitoring deployment
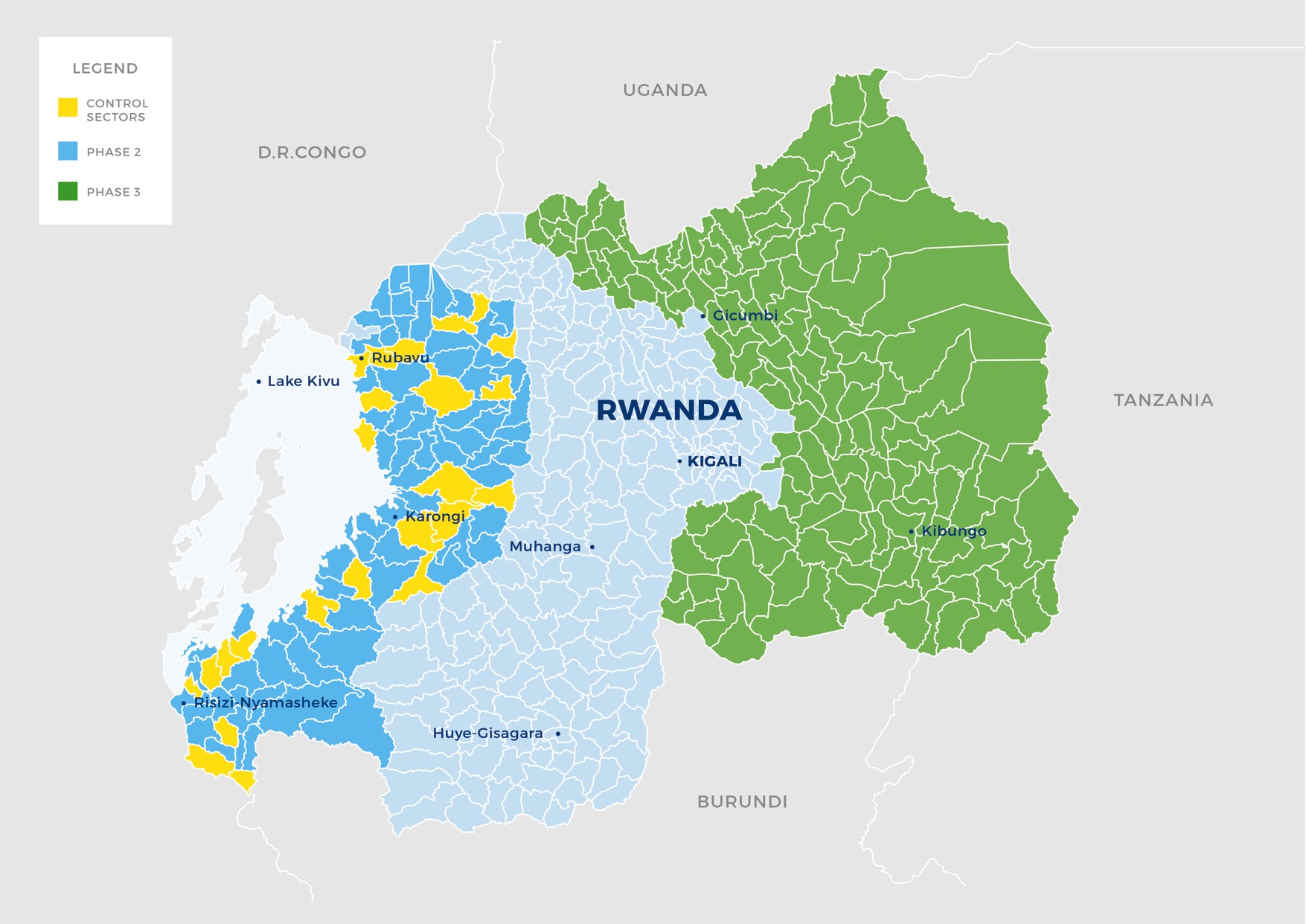
Key Results — Tubeho Neza Trial
Health Outcomes (Children Under 5)
- 29% reduction in 7-day prevalence of diarrhea
- 25% reduction in acute respiratory infections
- 97.5% reduction in fecal contamination of drinking water
- 38% reduction in cryptosporidium seroconversion
Air Quality — A Cautionary Finding
- Personal PM2.5 exposure remained unchanged despite improved cookstoves
- Stove stacking: traditional fire use increased from 24% to 49% over study period
The Adherence Problem
- Self-reported filter use: 67%
- Sensor-detected filter use: 37%
- Self-reported stove use: 84%
- Sensor-detected stove use: 37%
- Reported use declined: 75% → 68% → 65% across survey rounds
Economics
- 5-year programme cost: ~$12 million
- Estimated 5-year benefit: >$66 million
- Fuelwood savings: 65,000 tons — enough to reverse regional deforestation
Sources: Kirby, Nagel et al. (2019) PLoS Medicine; Thomas et al. (2018) Lancet Planetary Health; Thomas (2019) The Conversation
Technology & Digital Monitoring
Water Filters
- LifeStraw Family 2.0 household water filters
- Significant microbiological effectiveness reducing E. coli contamination
- Free distribution with carbon waiver for credit generation
Remote Sensing Innovation
- Electronic sensors remotely transmitting usage data
- Sensor-reported use was substantially lower than self-reported use
- Demonstrated critical value of objective digital monitoring
- Published in ACS Environmental Science & Technology
Carbon Credit Model
- Pay-for-performance model funded by voluntary carbon credits
- Health, livelihood, and environmental benefits substantially outweighed costs
- Fuel savings and averted healthcare costs = largest economic gains
Scale, Carbon Finance & Lessons Learned
Scale
- 101,000 households received filters + cookstoves (2014)
- 250,000 additional cookstoves distributed (2015) reaching ~1 million more people
- First-ever UN CDM and Gold Standard programmes earning carbon credits for water treatment
Carbon Credit Financing Model
- Carbon credit revenue funded distribution, training, and monitoring
- Did not rely on traditional aid/USAID funding — prescient given the 2025 USAID shutdown
- Now expanded via Virridy Carbon to Rwanda, Burundi, DRC, Madagascar, Kenya, Tanzania
Key Lessons
- Self-report ≠ reality — sensor data revealed ~2x overestimation of use
- Adherence declines — sustained engagement requires ongoing CHW visits
- Stove stacking — households used both improved and traditional stoves, limiting air quality gains
- Water treatment worked, cookstoves didn't — 97.5% water quality improvement vs no PM2.5 change
- Integration matters — combining with Rwanda's existing CBEHPP infrastructure improved reach
- Alternative financing — carbon credits provide sustainable revenue independent of aid budgets
Published Research (13 Papers)
| Title | Journal | Link |
|---|---|---|
| Health, livelihood, and environmental impacts of the Tubeho Neza programme | The Lancet Planetary Health | Open |
| Effects of adding household water filters to Rwanda's CBEHPP | Nature — npj Clean Water | Open |
| Assessing Impact of Water Filters and Cookstoves: A Randomised Controlled Trial | PLOS ONE | Open |
| Designing and Piloting a Program to Provide Water Filters and Cookstoves | PLOS ONE | Open |
| Cost-benefit analysis of livelihood, environmental and health benefits | ScienceDirect | Open |
| Use, microbiological effectiveness and health impact of a household water filter | ScienceDirect | Open |
| Study design of a cluster-randomized controlled trial | ScienceDirect | Open |
| Process evaluation and assessment of use | BMC Public Health | Open |
| Use of Remotely Reporting Electronic Sensors | ACS Env. Sci. & Tech. | Open |
| Integration of Household Water Filters with Community-Based Sanitation | MDPI Sustainability | Open |
| Geospatial-temporal, demographic, and programmatic adoption characteristics | Cogent Engineering | Open |
| Assessing use, exposure, and health impacts (Dissertation) | Semantic Scholar | Open |
| Lessons from Rwanda on tackling unsafe drinking water and air pollution | The Conversation | Open |
From Research to Methodology
The Tubeho Neza trial is used throughout the next section as a detailed case study for understanding research methodology — from study design and bias to statistical analysis and causal inference.
Study Design
Cluster RCT, 96 sectors, 3:1 randomization
Measurement
Self-report vs sensors, information bias
Analysis
GEE regression, clustering, missing data
Causal Inference
Counterfactuals, confounding, ITT analysis
Research Methodology
Methodological Considerations in Evaluating Global Health Interventions
Applying Methodology to Tubeho Neza
We now use the Rwanda water filter & cookstove trial (covered in the previous section) as a running case study for research methodology.
The core evaluation questions that will drive this section:
- Did this program actually reduce diarrhea in children under 5? Acute respiratory infections?
- Did it improve household water quality? Personal air quality (PM2.5)?
- How do we know the measured effects are real and not artefacts of bias?
Each topic below will reference specific Rwanda data to illustrate the methodology in action.
Published: Kirby, Nagel et al. (2019) PLoS Medicine | Design: Nagel, Kirby et al. (2016) CCTC
Biased Approaches to Evaluation
Biased Approach #1: Before vs. After
Diarrhea prevalence drops from 15% before distribution to 9% after. Tempting conclusion: a 40% reduction.
- Seasonality: The rainy season ended between measurements — diarrhea is seasonal
- Concurrent changes: Rotavirus vaccine campaigns, economic growth, other WASH programs
- Regression to mean: Starting during a disease spike means prevalence naturally returns to average
Before/after comparisons confound the intervention effect with all temporal changes.
Biased Approach #2: Users vs. Non-Users
Filter users have 40% less diarrhea — but users are more educated, practice handwashing, have better healthcare access.
This is selection bias: the comparison group is not exchangeable with the treatment group.
Rwanda Trial: Baseline diarrhea was 15.3% (intervention) vs 13.7% (control) — already different before intervention.
The Three Systematic Threats to Validity
We introduced confounding in the Epidemiology section. Here we add selection bias and information bias — the complete triad of systematic error.
Every epidemiological study faces two kinds of error. Random error shrinks with larger samples. Systematic error — bias — does not.
C — Confounding
A third variable distorts the exposure-outcome relationship because it is associated with both.
e.g., Wealthier households use filters AND have less diarrhea
S — Selection Bias
The study sample is not representative, or loss to follow-up differs systematically between groups.
e.g., Analyzing only clinic visitors misses healthy children
I — Information Bias
Systematic errors in how exposure, outcome, or covariates are measured.
e.g., Caregivers over-report filter use (social desirability)
Confounding, Selection Bias & Information Bias
Confounding: When a Third Variable Creates a False Association
Three criteria for a confounder: (1) associated with the exposure, (2) independently associated with the outcome, (3) not on the causal pathway.
Control methods: Design: randomization, restriction, matching. Analysis: stratification, regression, propensity scores.
Selection Bias: When Who Gets Studied Distorts Findings
- Loss to follow-up: Differential attrition biases the comparison
- Collider bias: Conditioning on a common effect creates spurious associations
- Volunteer/self-selection: Study volunteers differ systematically from non-volunteers
Information Bias: When Measurement Is Systematically Wrong
- Differential misclassification: Error differs between groups (recall bias, courtesy bias)
- Non-differential misclassification: Equal error across groups — biases toward the null
Recognizing Bias & Direction of Effects
| Stage | Critical Question | Bias Addressed |
|---|---|---|
| Design | Is treatment assignment independent of confounders? | Confounding |
| Design | Can participants be blinded to assignment? | Information |
| Enrollment | Is the sample representative of the target population? | Selection |
| Follow-Up | Is attrition differential between groups? | Selection |
| Measurement | Are outcomes assessed identically in all groups? | Information |
| Analysis | Have confounders been identified via DAG and adjusted? | Confounding |
Direction of Bias
- Non-differential misclassification: Toward null — dilutes the true effect
- Uncontrolled confounding: Either direction — depends on the confounder
- Differential misclassification: Either direction — unpredictable (recall bias, courtesy bias)
Study Design Hierarchy for Causal Inference
Each step down the hierarchy requires stronger assumptions to claim causation.
Randomized Controlled Trial (RCT)
Randomization creates exchangeable groups. Gold standard for causal inference.
Quasi-Experimental Designs
Exploit natural variation (DiD, RDD, ITS). No random assignment but clever design.
Cohort Study
Follow exposed/unexposed over time. Temporal ordering established.
Case-Control Study
Identify cases, select controls, look back. Efficient for rare outcomes.
Cross-sectional study: Snapshot — exposure and outcome measured simultaneously. Weakest for causation.
The Counterfactual & Potential Outcomes
Six months after distribution, 7-day diarrhea prevalence among children under 5 is 8.7%. Is that good or bad?
You cannot answer without knowing what the prevalence would have been without the intervention. This unobservable quantity is the counterfactual.
If counterfactual = 13%
29% reduction. Scale nationally.
If counterfactual = 8%
No effect. Don't waste resources.
The Potential Outcomes Framework (Neyman-Rubin)
For each child i: Yi(1) = outcome if treated; Yi(0) = outcome if not treated.
Causal effect = Yi(1) − Yi(0). The fundamental problem: we can only observe ONE potential outcome per child.
Average Treatment Effect (ATE) = E[Yi(1)] − E[Yi(0)]. Randomization makes the control group an unbiased estimate of the treated group's counterfactual.
Why Randomization Solves Confounding
Randomization ensures that, on average, treatment and control groups are identical in every way except the intervention — including unmeasured confounders.
What Randomization Gives You
Exchangeability (no confounding) • Unbiased ATE estimation • Valid statistical inference • Transparent, pre-specified analysis
What It Does NOT Give You
Protection from attrition bias • Protection from measurement bias • External validity / generalizability
Intention to Treat (ITT)
The ATE of being assigned to treatment, regardless of compliance. In Rwanda: the effect of living in a sector that received filters — not the effect of actually using the filter. ITT is the primary estimand for RCTs.
Rwanda Trial: Randomization at the sector level balanced observed covariates (age, sex, water source, sanitation type).
Individual vs. Cluster Randomization
Individual Randomization
Each person randomly assigned. Gold standard for independence. Problem: impractical for community-level interventions.
Cluster Randomization
Groups (villages, sectors) randomized. Prevents contamination. Cost: fewer independent units = less power. Requires GEE or mixed models.
Rwanda Trial: 96 sectors cluster-randomized 3:1. Sectors contain ~40 villages each. Stratified by district (7 districts). 3:1 ratio driven by programmatic goal of reaching 75% of the province in year 1.
Rwanda Trial: Two Studies in One
Sector-Level Study (Population Scale)
All ~82,000 children < 5 in 96 sectors. Data from health facility records and CHW reports.
Village-Level Sub-Study (Intensive Data)
174 village clusters, 1,582 households. 1:1 ratio via PPES sampling. Surveys, water sampling, PM2.5 monitoring, sensors.
Design lesson: When feasible, nest an intensive sub-study within a larger pragmatic trial.
Randomization vs. Random Sampling
Two distinct uses of randomness serving fundamentally different purposes.
Random Sampling
Purpose: Select who enters the study
Protects: External validity (generalizability)
Threat if absent: Results may not generalize
Randomization (Random Allocation)
Purpose: Assign who receives treatment
Protects: Internal validity (causal inference)
Threat if absent: Confounding
| With Randomization | Without Randomization | |
|---|---|---|
| With Sampling | Strongest: causal + generalizable (rare) | Generalizable, not causal (e.g., DHS) |
| Without Sampling | Causal, limited scope (most RCTs, e.g., Tubeho Neza) | Weakest: neither causal nor generalizable |
Key insight: Most trials have randomization without random sampling — establishing causation within a specific context.
Stratification & Quasi-Experimental Designs
Stratified Randomization
Ensures treatment/control balance on key variables. With only 96 clusters, pure randomization could produce imbalanced groups. Stratifying by district (7 districts) ensures proportional representation. Restricted randomization: generate many allocations, reject those with poor covariate balance.
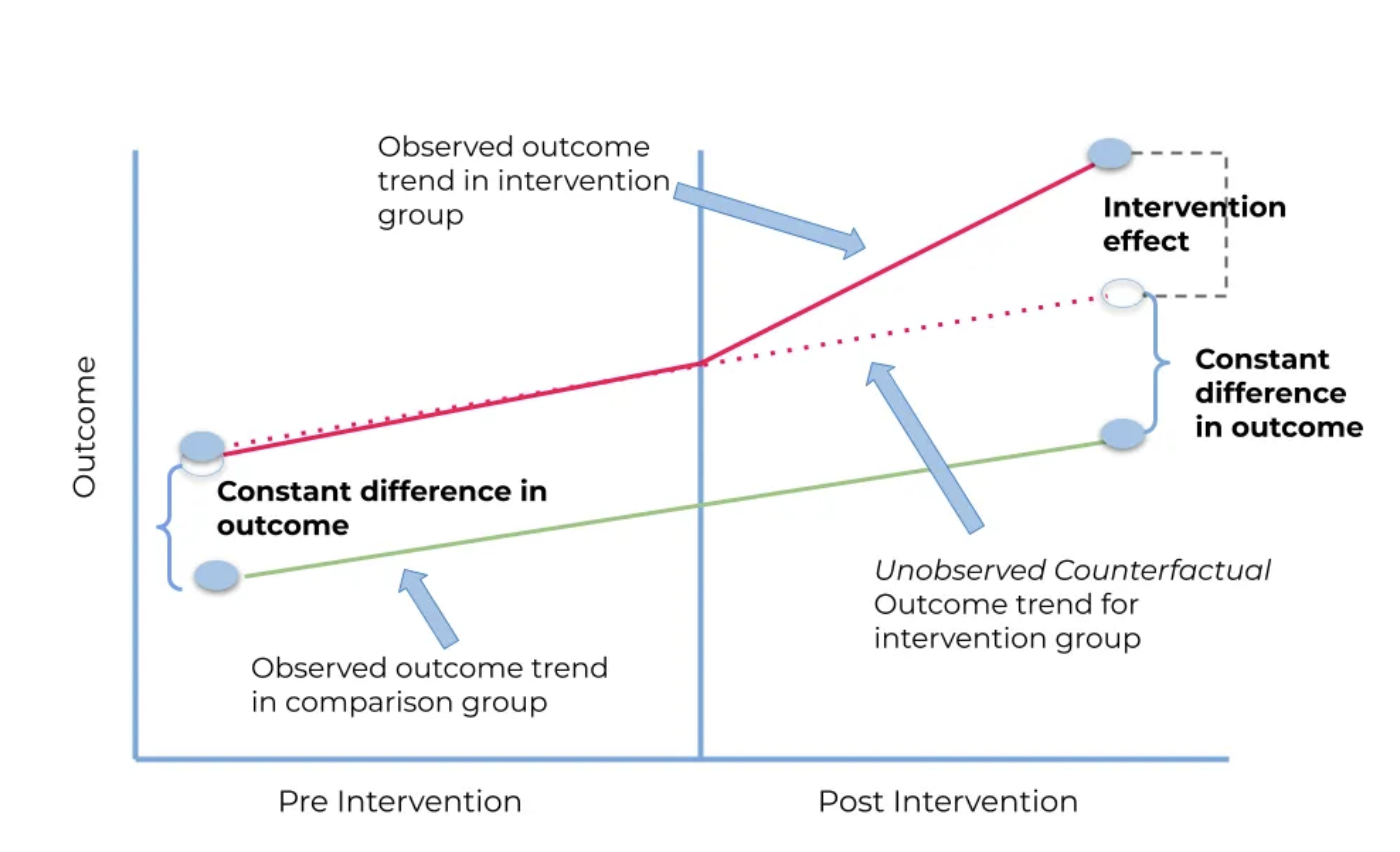
Difference-in-Differences (DiD)
Compare change over time in treated vs. untreated groups. ΔTreated − ΔControl = causal effect. Key assumption: parallel trends — both groups would have followed the same trajectory without intervention.
Other Quasi-Experimental Designs
- Regression Discontinuity (RDD): Exploit an eligibility cutoff. Households just above/below the Ubudehe threshold are similar but one gets the intervention. Estimates local effect at the cutoff.
- Interrupted Time Series (ITS): Track outcomes over time; look for level/slope change at intervention point. Requires long pre-intervention series (8+ data points).
Measurement & Statistics
Reliability & Validity of Measurement
Any measurement instrument must demonstrate both before its data can be trusted.
Reliability (Consistency)
A reliable instrument yields the same result repeatedly. Necessary but not sufficient — consistent measurement can still be consistently wrong.
Types: Test-retest (ICC, Pearson r) • Inter-rater (Cohen’s κ) • Intra-rater (ICC) • Internal consistency (Cronbach’s α)
Validity (Accuracy)
A valid instrument measures the construct it claims to measure. Without validity, reliability is meaningless.
Types: Content (expert panels) • Criterion (sensitivity/specificity, AUC-ROC) • Construct (CFA, convergent/discriminant)
Key Metrics
| Metric | Range | Poor | Moderate | Good | Excellent |
|---|---|---|---|---|---|
| ICC | 0–1 | < 0.50 | 0.50–0.75 | 0.75–0.90 | > 0.90 |
| Cohen’s κ | −1 to 1 | < 0.20 | 0.21–0.60 | 0.61–0.80 | > 0.80 |
| Cronbach’s α | 0–1 | < 0.60 | 0.60–0.70 | 0.70–0.90 | > 0.90 |
How Reliability & Validity Interact
Low R, Low V
Scattered, off-center. Needs complete redesign.
High R, Low V
Tightly clustered, off-center. Most deceptive: looks precise but systematically wrong.
Low R, High V
Scattered around center. On average correct but too noisy. Increase sample size.
High R, High V
Tightly clustered on center. The gold standard.
Pitfalls: Assuming reliability implies validity • Validating in one population but applying in another • Reporting only Cronbach’s α without factor structure
Disease Frequency: Incidence & Prevalence
Building on the introduction in the Epidemiology section — here we formalise the mathematical framework.
Incidence: New Cases Over Time
- Cumulative incidence (risk): New cases / Population at risk at start. e.g., 50/500 = 10% over 6 months
- Incidence rate: New cases / Person-time at risk. e.g., 50/250 person-years = 0.20/person-year. Accounts for variable follow-up.
Person-time: A child observed 6 months contributes 0.5 person-years.
Prevalence: Proportion with Disease
- Point prevalence: Cases at one time / Total population. A snapshot mixing new and ongoing cases.
- Period prevalence: Cases during a period / Population. "Has your child had diarrhea in the past 7 days?"
Prevalence = Incidence × Duration. Treatment that shortens episodes reduces prevalence without changing incidence.
Rwanda Trial: Primary outcome was 7-day period prevalence of caregiver-reported diarrhea and ARI. Repeated cross-sectional visits at ~4-month intervals.
Measures of Association: Relative & Absolute
Relative Measures
Rwanda Trial primary estimand: Prevalence Ratio from log-binomial GEE.
Values < 1 indicate a protective effect; > 1 indicates increased risk.
Absolute Measures
- Risk/Prevalence Difference: RD = Risk(exposed) − Risk(unexposed). Rwanda diarrhea: 8.7% − 12.9% = −4.2 percentage points
- Number Needed to Treat: NNT = 1/|RD|. Rwanda: 1/0.042 ≈ 24 households per case prevented in a 7-day window
Relative measures tell you how strong the effect is. Absolute measures tell you how much disease you actually prevent. Always report both.
Self-Report vs. Sensor & Evaluation Design
Filter use declined: 75.5% → 67.6% → 64.8%. Traditional stove use increased: 24.1% → 49.4% ("stove stacking").
Implications for Evaluation Design
- Triangulate: Self-report + observation + sensor + biomarker. Avoid reliance on a single method.
- Negative controls: Include outcomes that shouldn't be affected (Rwanda: toothache). If treatment reduces toothache, you have a bias problem.
- Blinding matters: Unblinded trials with subjective outcomes overestimate effects. Pooled masked HWT trials found no significant effect on diarrhea.
- Plan measurement validation: Budget for sensor sub-studies and spot-checks — these are essential, not extras.
The best study design in the world is undermined by poor measurement.
The Core Problem of Statistical Inference
We want to learn about a population, but we can only observe a sample.
Population
Parameters (fixed, unknown): True mean diarrhea prevalence across all children under 5 in Western Province, Rwanda
Sample
Statistics (variable, calculated): Observed prevalence of 8.7% from a survey of 2,000 households in 30 randomly selected villages
Key Concepts
- Sampling distribution: Distribution of a statistic across all possible samples of the same size
- Central Limit Theorem: Sampling distribution of the mean approaches normal as n increases
- Standard error: SD of the sampling distribution — measures estimate precision. Larger samples → smaller SEs
Key intuition: Probability distributions let us quantify uncertainty — which results would be common vs. surprising given a particular assumption.
The Logic of Hypothesis Testing
1. Assume No Effect
H0: Filter distribution has no effect on diarrhea prevalence.
2. Calculate Expected
Under H0, how much would prevalence vary between groups by chance?
3. Compare Observed
You observed a 4.3 pp difference. Test statistic t = 3.7.
4. Quantify Surprise
p = 0.002. Only 0.2% of random samples would show this large a difference.
Proof by contradiction: assume no effect exists, show the data would be very unlikely under that assumption, conclude the effect is probably real.
Two Ways to Be Wrong
| Reality: H0 TRUE | Reality: H0 FALSE | |
|---|---|---|
| Reject H0 | Type I Error (α) — false positive | Correct (Power = 1 − β) |
| Fail to reject | Correct (true negative) | Type II Error (β) — false negative |
P-Values & Confidence Intervals
The Epi section introduced CI interpretation and NNT. Here we examine what p-values actually mean — and what they do not.
What the P-Value IS
The probability of observing data at least as extreme as your result, assuming H0 is true. p = 0.03 means: if there were truly no effect, you'd see this result only 3% of the time.
What the P-Value is NOT
- NOT the probability that H0 is true
- NOT the probability of a false positive
- NOT a measure of effect size
α = 0.05 is a convention, not a law. Some fields use 0.01 or 0.10. Set before analyzing data.
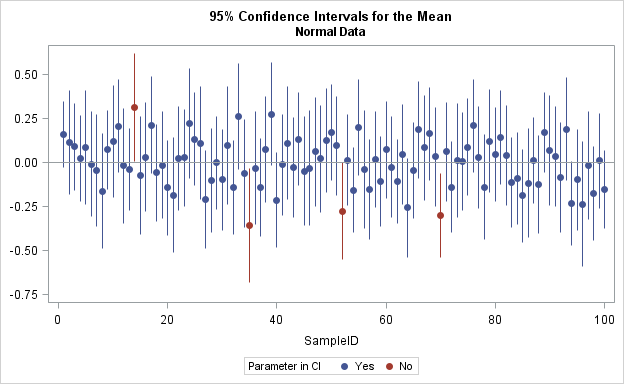
Confidence Intervals: Beyond Yes/No
If you repeated your study 100 times and computed a 95% CI each time, approximately 95 of those intervals would contain the true parameter. CIs provide the range of plausible effect sizes.
Choosing the Right Statistical Test
Before choosing a test, answer three questions: (1) What is your outcome variable? (2) How many groups? (3) Are assumptions met?
| Outcome | Scenario | Parametric | Non-Parametric |
|---|---|---|---|
| Continuous | 1 sample vs. known value | One-sample t-test | Wilcoxon signed-rank |
| 2 independent groups | Independent t-test | Mann-Whitney U | |
| 3+ groups | One-way ANOVA | Kruskal-Wallis | |
| Categorical | 2×2 independent | Chi-square test (Fisher’s exact if cell < 5) | |
| Paired before/after | McNemar’s test | ||
| Multiple predictors | Logistic regression | ||
| Time-to-event | Estimate/compare curves | Kaplan-Meier / Log-rank test | |
| Model with covariates | Cox proportional hazards regression | ||
Go non-parametric when: n < 30 and non-normal • Skewed data (income, costs) • Ordinal scales (Likert, staging)
Correlation, Regression & Survival Analysis
Correlation
- Pearson’s r: Both continuous and normal. Linear relationship. e.g., income vs. water quality
- Spearman’s rho: Ordinal or non-normal. Monotonic relationship. e.g., education level vs. health knowledge rank
Regression
- Linear regression: Continuous outcome. Y = b0 + b1X + e. e.g., predict child BMI from diet and activity
- Logistic regression: Binary outcome. Log-odds as linear function. e.g., predict diarrhea Y/N from WASH variables
- Poisson / Negative binomial: Count outcome. Rate of events per unit time. e.g., clinic visits per month
Survival Analysis
- Kaplan-Meier: Estimate survival curves. Handles censoring
- Log-Rank test: Compare survival between 2+ groups
- Cox regression: Model hazard with covariates. Produces hazard ratios
Statistical Test Decision Tree
What is your outcome variable?
Continuous
1 sample → t-test / Wilcoxon
2 groups → t-test / Mann-Whitney
3+ groups → ANOVA / Kruskal-Wallis
Paired → Paired t / Wilcoxon
Categorical
Independent → Chi-square / Fisher’s
Paired → McNemar’s test
Model → Logistic regression
Time-to-Event
Estimate → Kaplan-Meier
Compare → Log-rank test
Model → Cox regression
Quick Rules of Thumb
- Continuous outcome + 2 groups → start with a t-test
- Binary outcome → chi-square for comparison, logistic regression for modeling
- Censored follow-up time → survival analysis (Kaplan-Meier, log-rank, Cox)
- Clustered data → mixed models or GEE, not standard tests
Advanced Topics
Clustering, Missing Data & Generalizability
Rwanda Trial: Primary Analysis in Detail
The Analytic Pipeline
- Outcome: Binary (diarrhea yes/no in past 7 days)
- Model: Log-binomial regression → directly estimates prevalence ratio
- Clustering: GEE with exchangeable working correlation, robust (sandwich) SEs at village level
- Covariates: Child age (months) and sex only — minimal adjustment since randomization handles confounding
- Weights: Sampling weights to account for PPES design in village-level sub-study
Water quality improved significantly. Air quality did not — consistent with stove stacking behavior detected by sensors.
The Issue of Clustering
Children within the same village share water sources, sanitation, disease ecology, climate, economic conditions, CHW quality, and health facility access. Their health outcomes are correlated — not independent.
Intraclass Correlation & Design Effect
ICC = σ²(between) / [σ²(between) + σ²(within)] — proportion of variance due to between-cluster differences.
Design Effect (DEFF) = 1 + (m − 1) × ICC, where m = average cluster size. Effective sample size = n / DEFF.
| Level | Outcome | ICC | Design Effect |
|---|---|---|---|
| Within-village | Diarrhea | 0.02 | 1.18 (m=10) |
| Within-village | ARI | 0.04 | 1.36 (m=10) |
| Sector-level | Diarrhea | — | 9.5 |
| Within-child (repeated) | Diarrhea | 0.09 | — |
Ignoring Clustering & Sample Size
What Happens When You Ignore Clustering
If you analyze 5,000 children from 10 clusters as independent observations, your nominal 5% significance level may actually be 20–30%. This is one of the most common methodological errors in global health research.
Sample Size Under Clustering
The number of clusters matters more than individuals per cluster.
Clusters needed per arm: k = (Zα + Zβ)² × DEFF × 2σ² / δ². Adding more people per cluster gives diminishing returns once m × ICC > 1.
Better to have 20 clusters of 50 than 10 clusters of 100. Always calculate cluster-adjusted sample sizes.
Analytic Solutions for Clustering
Cluster-Robust SEs
"Sandwich" standard errors. Inflate SEs to account for within-cluster correlation. Requires ≥30 clusters. Simplest solution.
GEE
Generalized Estimating Equations. Specify working correlation structure. Robust SEs protect against misspecification. Population-averaged. Used for Rwanda primary analysis.
Mixed Models
Random effects / multilevel models. Estimate cluster-specific parameters. Handle multiple nesting levels. Cluster-specific interpretation.
For policy questions ("what’s the average effect?"), GEE is preferred. For prediction ("what will happen in this village?"), mixed models are preferred.
Rwanda Trial: GEE with exchangeable working correlation and robust SEs, clustering at village level.
Missing Data Mechanisms
Rubin’s classification defines why data are missing — and determines which analytic methods are valid.
MCAR — Least Concern
Missingness unrelated to any data. Loss of power but no bias. Complete-case analysis valid.
e.g., Lab machine randomly malfunctions
MAR — Moderate Concern
Missingness depends on observed data. Biased if ignored. Recoverable with MI or ML methods.
e.g., Younger participants miss follow-up
MNAR — Greatest Concern
Missingness depends on the unobserved value itself. Biased under all standard methods. Requires sensitivity analyses.
e.g., Depressed patients don’t complete depression scale
Analytic Solutions for Missing Data
| Method | Valid Under | How It Works |
|---|---|---|
| Complete-Case Analysis | MCAR | Delete cases with missing values. Simple but wasteful. Biased unless MCAR. |
| Single Imputation | MCAR | Replace with mean/median/LOCF. Underestimates variance. Rarely recommended. |
| Multiple Imputation (MI) | MAR | Create m complete datasets (20–50) with plausible imputed values. Pool results via Rubin’s rules. |
| Maximum Likelihood (ML) | MAR | Estimate parameters directly from observed data likelihood (EM, FIML). No imputed datasets needed. |
| Inverse Probability Weighting | MAR | Weight complete cases by inverse probability of being observed. Combines with MI for doubly robust estimation. |
| Sensitivity Analysis | MNAR | Vary assumptions about missing values. Pattern-mixture models, selection models, tipping-point analyses. |
External Validity: Not All Water Treatment Works
Randomized trials of chlorination in Bangladesh, Kenya, and Zimbabwe found NO significant effect on childhood diarrhea.
Pathogen Profile
Chlorine is ineffective against Cryptosporidium. LifeStraw removes it through physical ultrafiltration. Intervention type matters.
Measurement & Blinding
Chlorination trials with blinded outcomes (sham chlorine) found no effect. Unblinded self-reported outcomes may overestimate effects.
The generalizability question isn’t "does water treatment work?" It’s "which treatment, against which pathogens, in which context, with what delivery model?"
Internal vs. External Validity
The Rwanda trial has strong internal validity (cluster-RCT, pre-registered, large sample). But results are specific to: Western Province, Rwanda | Poorest quartile | Rural | LifeStraw + EcoZoom | CHW-delivered with carbon credit financing.
Effect Modification: Why Effects Vary
Treatment effects are not universal constants. They vary across subgroups and contexts.
Biological Modifiers
- Age: children < 2 more susceptible
- Nutritional status
- HIV/immune status
- Pathogen profile: filter vs. chlorine
Contextual Modifiers
- Baseline water quality
- Baseline disease burden
- Competing transmission routes
Implementation Modifiers
- CHW network quality
- Supply chain reliability
- Cultural acceptability
- Government support
Always report subgroup analyses and discuss which modifiers might limit transportability. Rwanda’s strong CHW system is unusual — replication elsewhere may yield smaller effects.
Efficacy → Effectiveness → Scale
Why Effects Shrink at Scale
- Adherence: Self-reported filter use declined 75.5% → 64.8%. Sensor data: actual use ~37%.
- Stove stacking: Traditional fire use increased 24.1% → 49.4%. No exclusive adoption → no air quality improvement.
- Implementation variation: Hundreds of CHWs with varying training, supply chain delays, seasonal access challenges.
Key Takeaways
Health is shaped by systems
Determinants of health extend far beyond healthcare — water, sanitation, air quality, governance, and poverty all drive disease burden.
Measurement matters
Self-report ≠ reality. Sensors, objective measurement, and rigorous study design are essential to understanding what actually works.
Efficacy ≠ effectiveness
Interventions that work in trials often fail at scale. Adherence, implementation fidelity, and local context determine real-world impact.
Engineers build the solutions
Water filters, sensors, surveillance systems, and monitoring infrastructure — engineering is where global health evidence becomes action.
Global Burden of Disease Lab
Water quality QMRA & air quality cost-effectiveness analysis using R, GBD Compare, and HAPIT.
Open Full Lab Assignment →